Biography
I received my Master Degree in Computer Engineering from Northeastern University (in Boston), advised by Prof. Lu Wang (now at UMich). I'm also privileged to work with Prof. Lifu Huang from Virginia Tech (now at UC Davis).
I'm generally interested in natural language processing, machine learning and generative models. I am currently working on evaluating and enhancing the trustworthiness, reasoning, and creativity of LLMs and VLMs, with applications in NLP and Multimodal scenarios. For core natural language processing (NLP) problems, I have been working on coherent and controllable long text generation and summarization. I'm open to potential collaborations and feel free to drop me an email.
Selected Publications
- Praxis-VLM: Vision-Grounded Decision Making via Text-Driven Reinforcement Learning Zhe Hu, Jing Li, Zhongzhu Pu, Hou Pong Chan, Yu Yin ArXiv 2025
PDF Code
-
When 'YES' Meets 'BUT': Can Large Models Comprehend Contradictory Humor Through Comparative Reasoning?
Tuo Liang*, Zhe Hu*, Jing Li, Hao Zhang, Yiren Lu, Yunlai Zhou, Yiran Qiao, Disheng Liu, Jeirui Peng, Jing Ma, Yu Yin[*equal contribution] ArXiv 2025
PDF Project 🤗 Dataset
- Synchronized Video-to-Audio Generation via Mel Quantization-Continuum Decomposition Juncheng Wang, Chao Xu, Cheng Yu, Lei Shang, Zhe Hu, Shujun Wang, Liefeng Bo CVPR 2025
PDF Code
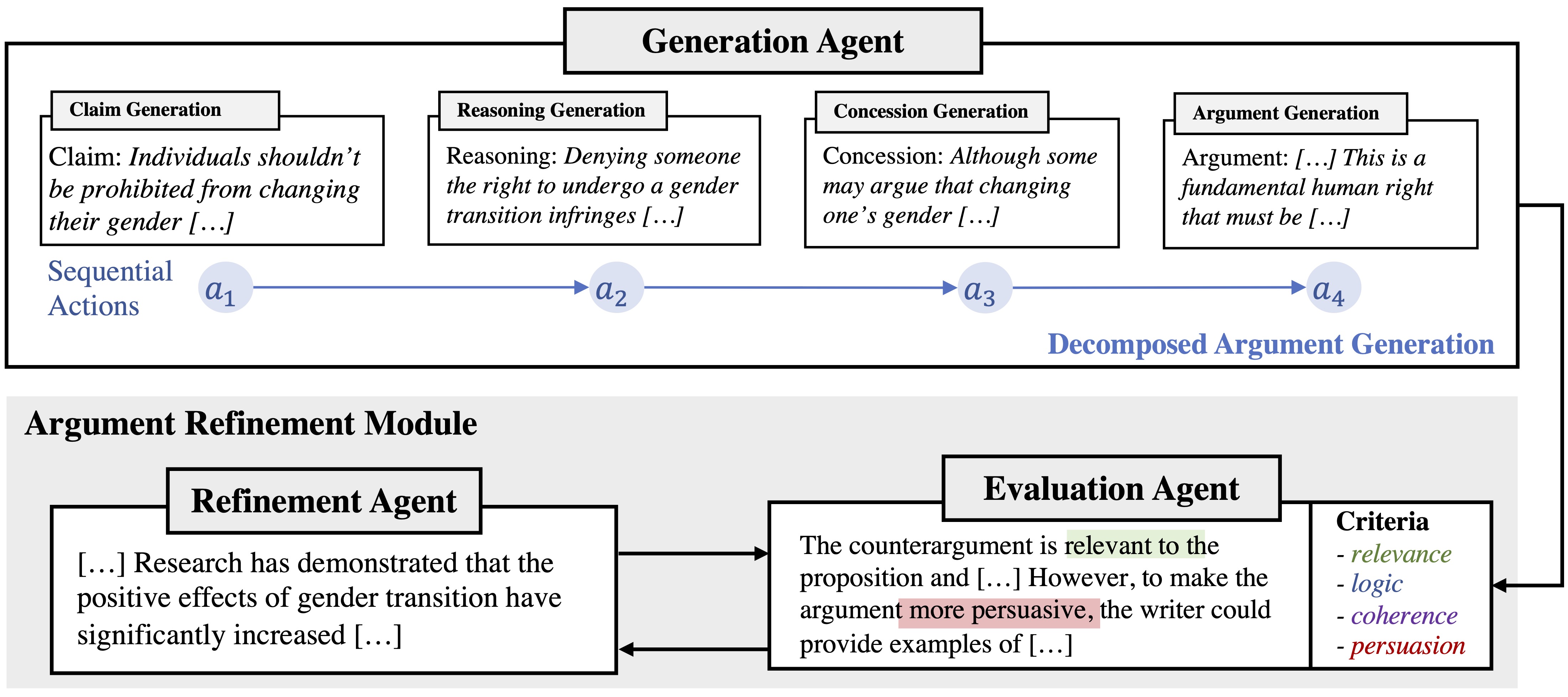
- Debate-to-Write: A Persona-Driven Multi-Agent Framework for Diverse Argument Generation Zhe Hu, Hou Pong Chan, Jing Li, Yu Yin COLING 2025, short paper
PDF Code
- STAF-LLM: A scalable and task-adaptive fine-tuning framework for large language models in medical domain Tianhan Xu, Ling Chen, Zhe Hu, Bin Li Expert Systems with Applications 2025
- Cracking the Code of Juxtaposition: Can AI Models Understand the Humorous Contradictions Zhe Hu*, Tuo Liang*, Jing Li, Yiren Lu, Yunlai Zhou, Yiran Qiao, Jing Ma, Yu Yin[*equal contribution] NeurIPS 2024, Oral (Top 1.7%)
PDF Project ▶️ Video Abstract

 : A Benchmark for Vision-Grounded Decision-Making with Human Values
: A Benchmark for Vision-Grounded Decision-Making with Human Values